The Problem Discovery:
It was observed on or around 2020.02.22 that a number of TRB nodes were getting "wedged". It was initially thought that there might be something problematic about block 618405 causing TRB to be rendered in a still-running, yet defunct state. Specifically, TRB would still have connections to peers, yet, no new blocks were being accepted or processed from peers, and notably, RPC commands would "hang" on the command line and not be issued a response. Also alarming, a major increase in RAM usage as well as CPU utilization (on one logical core) going at or near 100%. During this initial period of discovery, node operators were able to resume TRB operations with a full restart of the node. However, during the first 48 hours of the first instance of the problem, most if not all TRB operators were getting the same problem, repeatedly.
I had noticed in my own TRB debug.log that I was seeing upwards of 32k 'getdata: for block' requests from a single IP address. The protocol obviously allows for this behavior. In fact, main.cpp:ProcessMessage(...) allows for up to 49,999 'inv' entries (for blocks or transactions) to be requested in a single 'getdata' message, from a single peer. It piqued my interest when tens of thousands of these 'getdata for: block' requests were coming in, and during or just after, the node was rendered defunct. This, too, on my end, was reproducing reliably. As it turns out, nothing is wrong with block 618405, it was simply a red herring.
bvt had his gdb connected to his node and was able to debug when the problem occurred. His helpful information was a good starting point for deeper investigation.
My Own Debugging:
On February 26th, asciilifeform created a tool called wedger.py which simply will take an arbitrary list of blocks (and their specific hashes) and construct a single 'getdata' message (in this case, containing 49,999 inv requests for blocks) which is sent to a given node, requesting the blocks to be sent back. This is useful to reproduce the problem since one can easily request 49,999 blocks and see what happens with gdb attached. As soon as I used this against my node, it immediately wedged [debug.log], just as it had previously.
With the wedger.py in hand, bvt's conditions and print statements (as well as a number of my own), I conducted some extensive debugging while gdb was attached to a live TRB.
As previously stated: an external node may create up to 49,999 'inv' requests in a single 'getdata' message. For each of these requests, TRB makes a unique message response containing header and the block. These are then appended to a byte stream vector called 'vSend'. I observed that 'vSend' fills up with the responses to the request -- to the tune of greater than 4Gb. During my testing it typically takes about 4400 respons messages to fill vSend (using recent blocks from the blockchain, of which most are just under the 1Mb size limit), rendering the vector greater than 32 bits in size. Upon each addition of a message to the vector, the beginning and end of the latest message are passed to util.h's Hash(...) routine. However, when the buffer has exceeded 4Gb, Hash(...) simply never returns, or at least, as far as I can tell.
A check does exist to ensure that the node does not attempt to send more than the -maxsendbuffer size in net.cpp:ThreadSocketHandler2; however, it seems that the mutex locking code surrounding this check prevents it from being called every time through. During testing with weger.py, I observed that TRB does appear to run the size check a small number of times before it gets perma-locked without release.
An Experimental Solution (For Blocks)
The exact surgical fix for this problem, as opposed to an (experimental) change, is to fix the locking code that is pervasive throughout all of TRB. This not only is challenging but very risky in my opinion.
Upon looking at main.cpp:ProcessMessage I can see that Satoshi did place a limiter on the amount of data sent for the 'getblocks' command. Why one exists here, and not for 'getdata', I'm not certain. Another curiosity is why this check divides the -maxsendbuffer size by two: I do not know. A possible experimental solution is to place a limiter check in the 'getdata' (for blocks) section. However, this is truly only one of two limiters that would be needed in the conditional block for 'getdata' commands of the ProcessMessage code. Examining this portion, I can see that 'getdata' commands fall into two categories; blocks and transactions.
The strictly experimental vpatch (signed with my mod6-vpatch-testing key) below only creates a limiter for 'getdata' commands for blocks. The code required to add a limiter for the transactions portion of the code is very similar; however, before I can provide such an experimental change, I need to create (or augment wedger.py) to generate requests of transactions that currently reside in the mempool. This shouldn't be inherently difficult, but will take time and testing. This will be covered in a separate article later.
Tests Conducted
I have been personally testing this change for nearly three weeks now; as has asciilifeform on two of his nodes, and I believe bvt has as well. I, nor asciilifeform, have had the same problem since the vpatch has been applied. I have bombarded my node numerous times with the wedger.py tool, as well as seeing sporadic instances of external clients requesting large numbers of blocks. These are now thwarted by the code change checking to ensure that we're not attempting to send back more than defined by -maxsendbuffer (default is 10Mb). I did also test to ensure that if this value is set to something different, the vpatch still works as expected: Having a higher or lower threshold, depending on the value defined at startup.
Additionally, I have conducted process memory tests with TRB, both without the patch applied, and with the patch applied. The pmap tests were started just after the launch of TRB (requires a PID), and captures a memory profile when connecting to the network, and then being in a steady state of execution. Then I've run the wedger.py tool against TRB, illustrating the growth of memory with and without the patch applied.
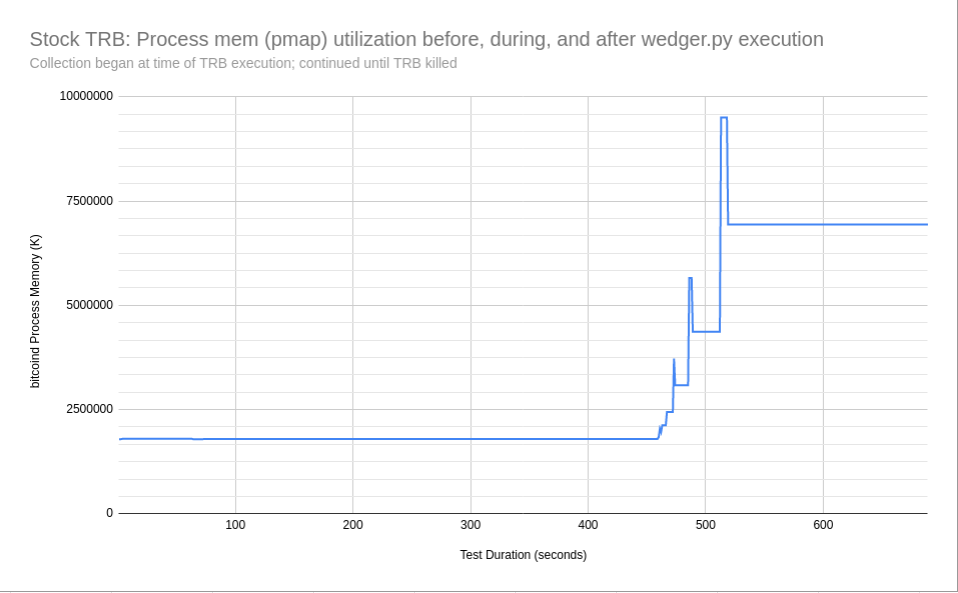
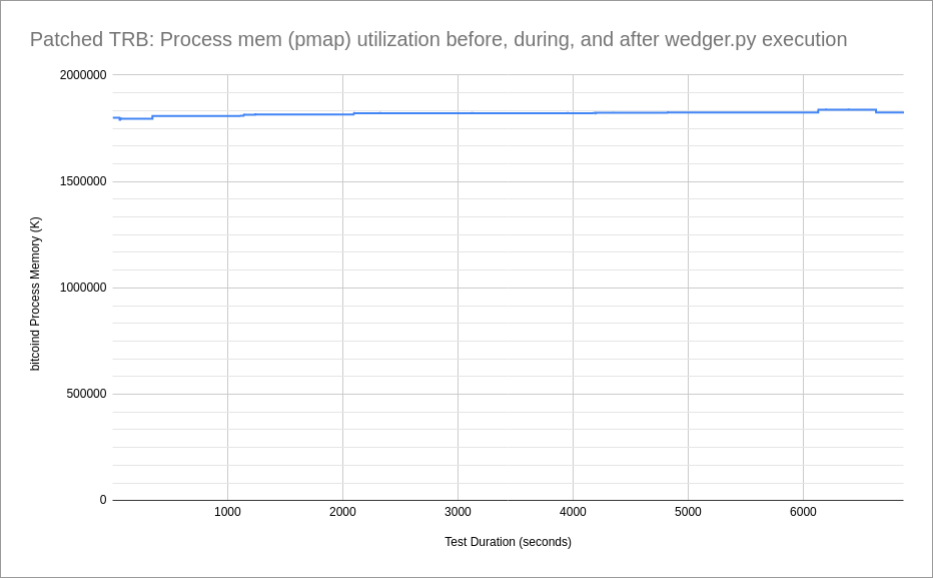
[...] a follow on to my previous entry, I wanted to take a moment and update where I am with the testing regarding 'getdata for [...]
Pingback by getdata for transactions « mod6's Blog — 2020/04/05 @ 00:16
There's a larger "select" loop at play; in theory the TRY_CRITICAL_BLOCK would simply get retried on the next pass if it fails and the socket remains writeable. What the locking accomplishes in the first place if peers are serviced by a single thread is unclear to me so far.
As for the change, if a new protocol limit is being added (as the Misbehaving(20) suggests), wouldn't it make more sense to limit based on something knowable to the peer like block count rather than total size?
Comment by Jacob Welsh — 2020/04/30 @ 18:22
@JFW #2:
The locking doesn't accomplish much. There, or anywhere in TRB, it was one of the orig. author's ritual substitutes for actually knowing what he's doing.
Re: "limit based on something knowable to the peer like block count" -- this would nail newly-built nodes, which entirely reasonably ask for 500+ at a time of the kB-sized early blocks.
Incidentally, TRB itself does not request large masses of blocks by-hash with 'getdata'. Seems to be exclusive to PRB (and attack scripts a la 'wedger') AFAIK.
Comment by Stanislav Datskovskiy — 2020/05/17 @ 00:55